KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
摘要
KVQuant 针对长上下文推理时 KV Cache 占用显存急剧膨胀 的瓶颈,提出“四步一体”超低比特量化方案:① 通道级 Key 量化,② RoPE 前 Key 量化,③ 灵敏度加权非均匀量化(nuqX),④ 向量级稠密-稀疏拆分。在 LLaMA-7B/13B/30B/65B、Llama-2、Llama-3 与 Mistral-7B 上实现 3-bit KV 缓存量化而感知困惑度 < 0.1,显存节省 最高 6.9×;借助定制 CUDA 核,可在 单张 A100-80GB 上跑 100 万 token 上下文,8 GPU 集群可达 1000 万 token,关键矩阵-向量乘加加速 ~1.7×。(arxiv.org, arxiv.org, arxiv.org, github.com)
1 问题定义与核心贡献
痛点:序列长度 LL 增大时,KV Cache 显存 O(L)O(L) 增长并成为主瓶颈;当权重已被 4-bit 压缩后,这一瓶颈更突出。(arxiv.org)
核心贡献:
Per-Channel Key Quantization:按通道而非按 token 量化 Key,缓解极值通道干扰。(arxiv.org, arxiv.org)
Pre-RoPE Key Quantization:在旋转位置编码前量化 Key,避免 RoPE 混频扩大动态范围。(arxiv.org, arxiv.org)
nuqX 灵敏度加权非均匀量化:离线校准时用损失敏感度指导 k-means 划分断点,显著提升 2/3-bit 精度。(arxiv.org, arxiv.org)
Dense-and-Sparse 拆分:每向量抽取 1 % 数值异常值做稀疏存储,其余稠密 2-4 bit 编码,既控误差又保并行性。(arxiv.org, arxiv.org)
自研 CUDA 核:在线打包 + RoPE on-the-fly + 稀疏乘法,Key/Value matvec 最多 1.7× 加速。(arxiv.org, arxiv.org)
2 关键技术解析
2.1 通道级 Key 量化
观察:Key 在 RoPE 之前存在“热点通道”极值,按 token 量化易拉大量化区间。
做法:对 Key 的通道维度分别统计区间并独立量化;Value 仍按 token 量化以避免误差累积。(arxiv.org)
效果:Llama-7B 3-bit PPL 从 10.9 降到 7.05;配合其它模块进一步降到 6.23。(arxiv.org)
2.2 RoPE 前量化
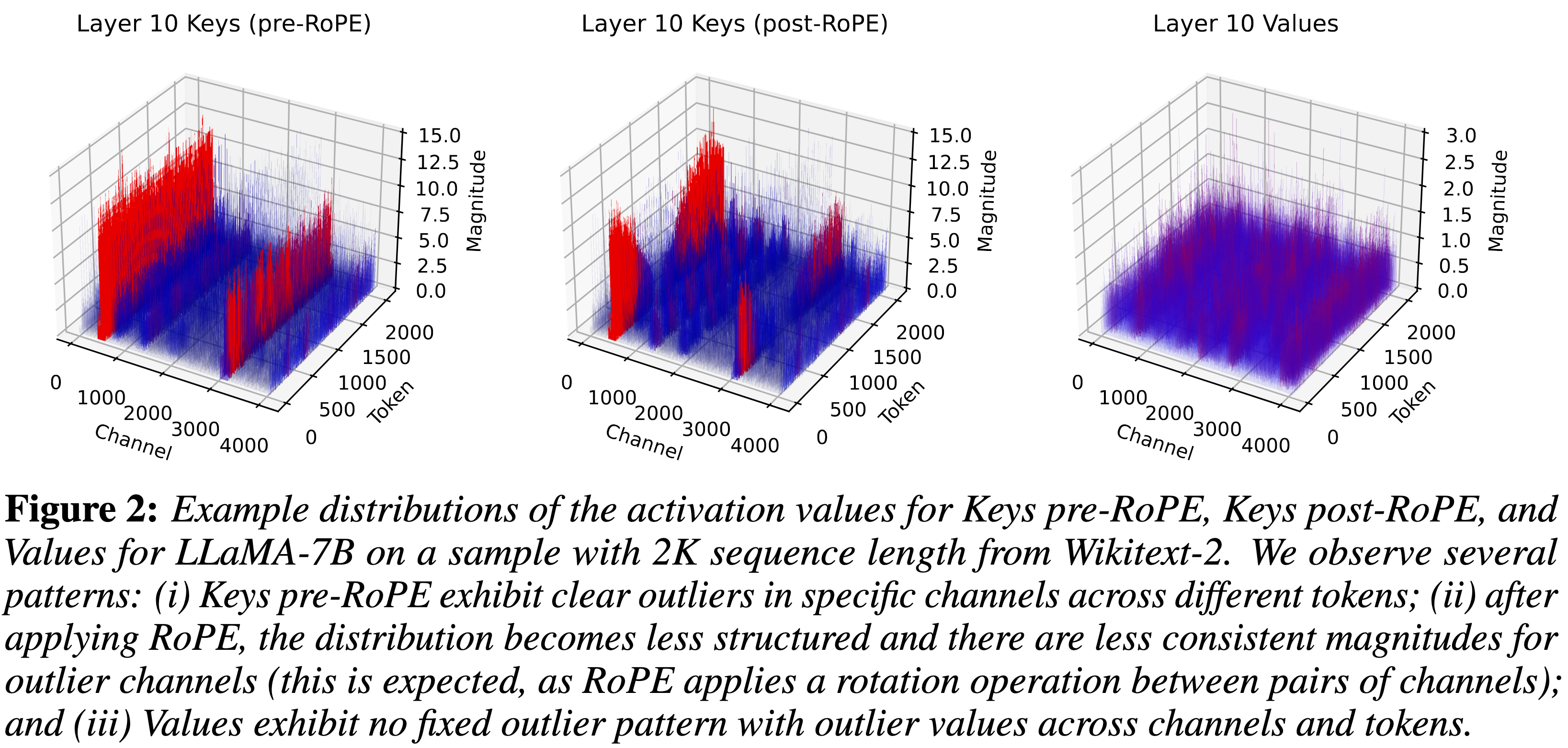
RoPE 会两两混合 Key 维度,放大不同尺度;先量化再乘 RoPE(推理时反向再乘)可减少量化失真,3-bit PPL 改善 ≈ 0.8。(arxiv.org)
2.3 nuqX:灵敏度加权非均匀量化
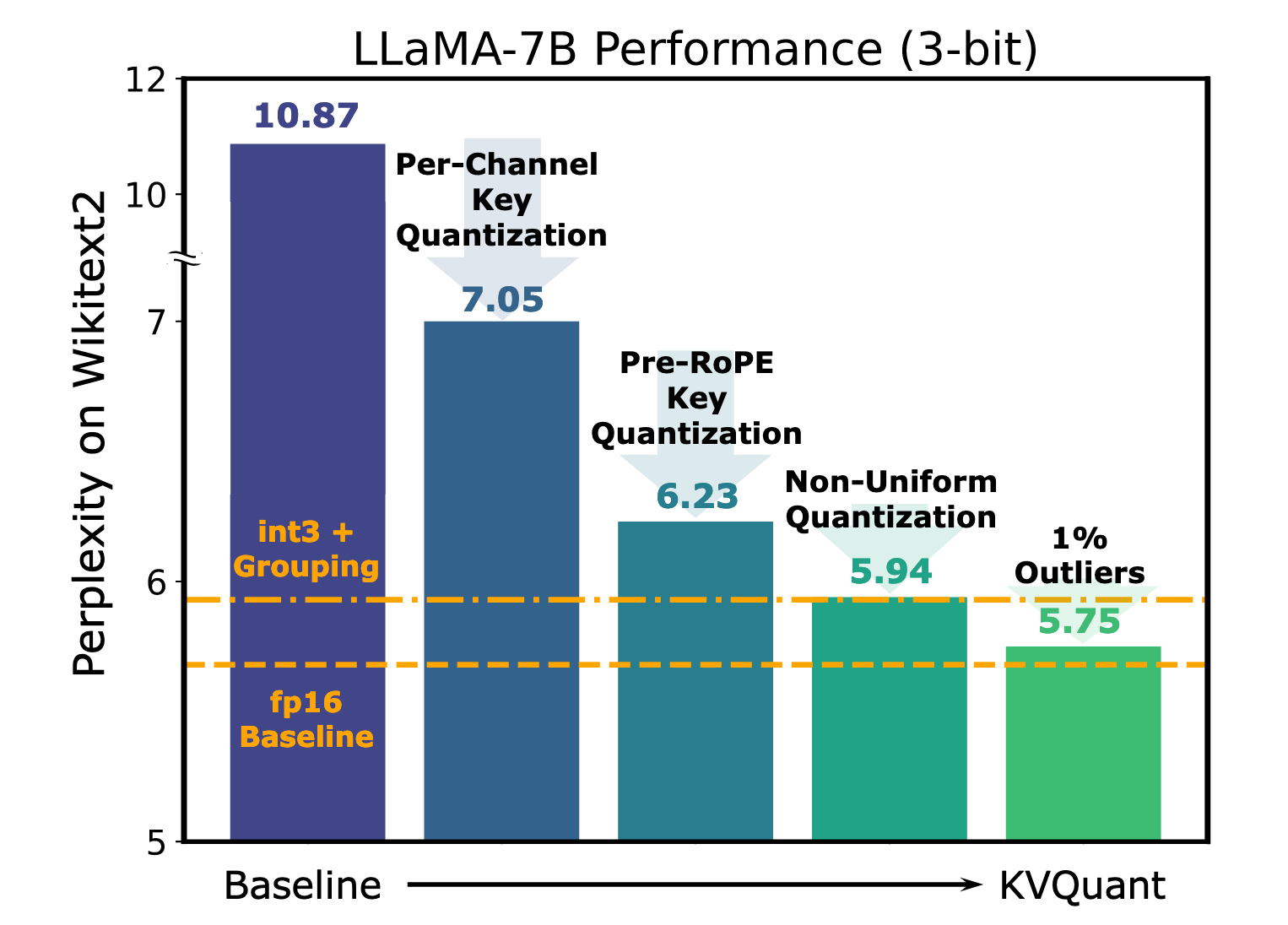
从图中可以看到,对于 KVcache,nuqX可以带来0.19的提升。
用校准集估计 ∇aL\nabla_a \mathcal{L} 作为灵敏度权重,对激活做 k-means 分桶(位宽由 X 指定,例如 nuq3)。
相比普通均匀 int3 与 NormalFloat-3,平均 PPL 改善 0.2-0.3。(arxiv.org)
2.4 Per-Vector Dense-and-Sparse Quantization 在 KVQuant 中的机制
向量级阈值切分
对每个 Key / Value 向量(长度 d)单独统计幅值分布。
选定阈值 T(按固定百分位或灵敏度指标)。
超过 T 的少量元素 → “稀疏(outlier) 子集”;其余 ≈ 99 % → “稠密(dense) 子集”。
双路径存储
稀疏子集 S:保存 (index, fp16 value) 对,通常 < 1 % -– 3 % 的元素,采用 CSR/COO 格式。
稠密子集 D:按向量本身的 min-max 区间或非均匀 nuqX 码本做 2-4 bit 量化,并用表查 LUT 打包。
融合推理内核
自研 CUDA kernel 同时:
解码 D → fp16;
取出 S 并做稀疏乘法;
将两路结果在寄存器中相加,再与 Query 完成 matvec。
因为绝大多数带宽来自低位稠密流,核总体 1.6 – 1.8 × 加速且显存 ≈ 4 – 6 × 缩减。
2.5 Attention-Sink Aware & 内核实现
论文还提出按“注意力沉”分布微调量化阈值,并在 kernel 中把 RoPE + Dequant + MatVec 融合;详见附录 P。(arxiv.org)
graph TD
Prompt-->K(Key)
Prompt-->V(Value)
K-->PCQ[Per-Channel Quant & Pre-RoPE]
V-->PTQ[Per-Token Quant]
PCQ-->NUQ
PTQ-->NUQ
NUQ-->DSQ[Dense/Sparse Split]
DSQ-->CUDA[Custom CUDA Kernels]
CUDA-->Cache[3-bit KV Cache]
Cache-->Attn[Attention Compute]
3 实验设计
4 结果分析
精度:
4-bit:平均 PPL 提升 < 0.02;3-bit < 0.1;2-bit < 0.5,相比 Atom/FlexGen 全面领先。(arxiv.org)
显存:Llama-7B 128 K 序列,KV 缓存从 64 GB→12 GB(3-bit),节省 4.8×;2-bit 时节省 6.9×。(arxiv.org)
长上下文:单 A100-80GB 可跑 1 M token;8 GPU 集群可达 10 M token。(arxiv.org)
速度:3-bit Key matvec 219 µs→126 µs;整体 KV matvec 加速 ~1.7×。(arxiv.org, arxiv.org)
5 优势与局限
6 未来方向
跨硬件迁移:将 nuqX + 稀疏核移植到 CPU/FPGA。
与滑动窗口/块稀疏注意力结合:进一步减少 KV 长度。
自适应 outlier budget:动态调整稠密-稀疏比例,兼顾速度与精度。
端到端权重-激活联合量化:与 SqueezeLLM 等权重量化融合,推向 2-bit 全链路。
工程实践:作者已在 GitHub 放出量化脚本、核代码与 LWM-1M 样例,一键复现长上下文推理。(github.com)