QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
本文系统解读 QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving,并突出其三项核心创新:
1)提出 QoQ 算法,在保持推理精度几乎无损的前提下,将权重、激活与 KV-cache 分别量化到 4 bit/8 bit/4 bit;
2)通过进阶分组量化与 SmoothAttention 缓解极低位宽带来的精度损失;
3)在系统层进行权重重排、寄存器级并行解量化和 KV4-友好的融合注意力,实现比 TensorRT-LLM 更高的吞吐与更低的成本。(arxiv.org, arxiv.org)
背景与动机
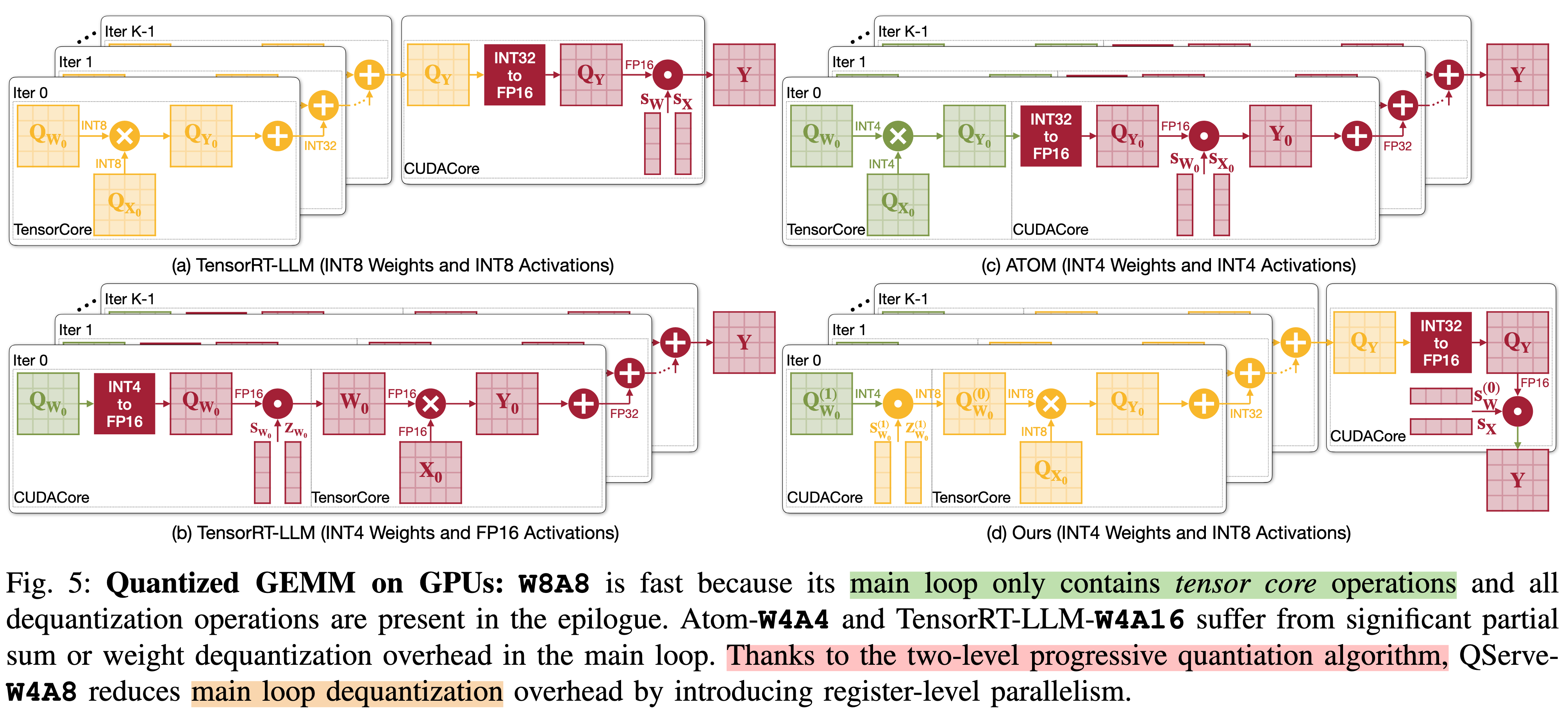
当采用传统 W4A4 量化时,权重与激活需在主循环里做 INT4→FP16 解量化,引入 20–90 % 的 CUDA-core 开销,导致实际吞吐不升反降(arxiv.org)。
作者指出:若把激活位宽放宽到 8 bit,就可以把解量化操作挪到高吞吐的 INT8 Tensor Core,避免 CUDA 核心瓶颈,从而兼顾精度与性能(hanlab.mit.edu)。
QoQ 算法:W4A8KV4 量化
1. 进阶分组量化(Progressive Group Quantization)
两级流程:先对权重做每通道 FP16-scale 的 INT8 量化,再把 INT8 中间表示压缩到 INT4;这样所有 GEMM 仍可运行在 INT8 Tensor Core 上,解量化仅需 INT4→INT8,省掉浮点操作(arxiv.org)。
保护区间:在第一级量化时对异常权重做裁剪,保证第二级再压缩时不会溢出,从而支持寄存器级并行解量化(arxiv.org)。
2. SmoothAttention:KV4 精度补偿
量化 KV-cache 到 4 bit 会放大注意力分布误差。SmoothAttention 通过 先对 Key 做对数量化友好的平滑变换,再把量化误差转移到未量化的 Query,显著降低损失(emergentmind.com, openreview.net)。
论文实验显示,在 Llama-3-8B 上 KV4 结合 SmoothAttention 的 perplexity 与 FP16 几乎一致,而直接 KV4 会下降 1.5 pp 以上(openreview.net)。
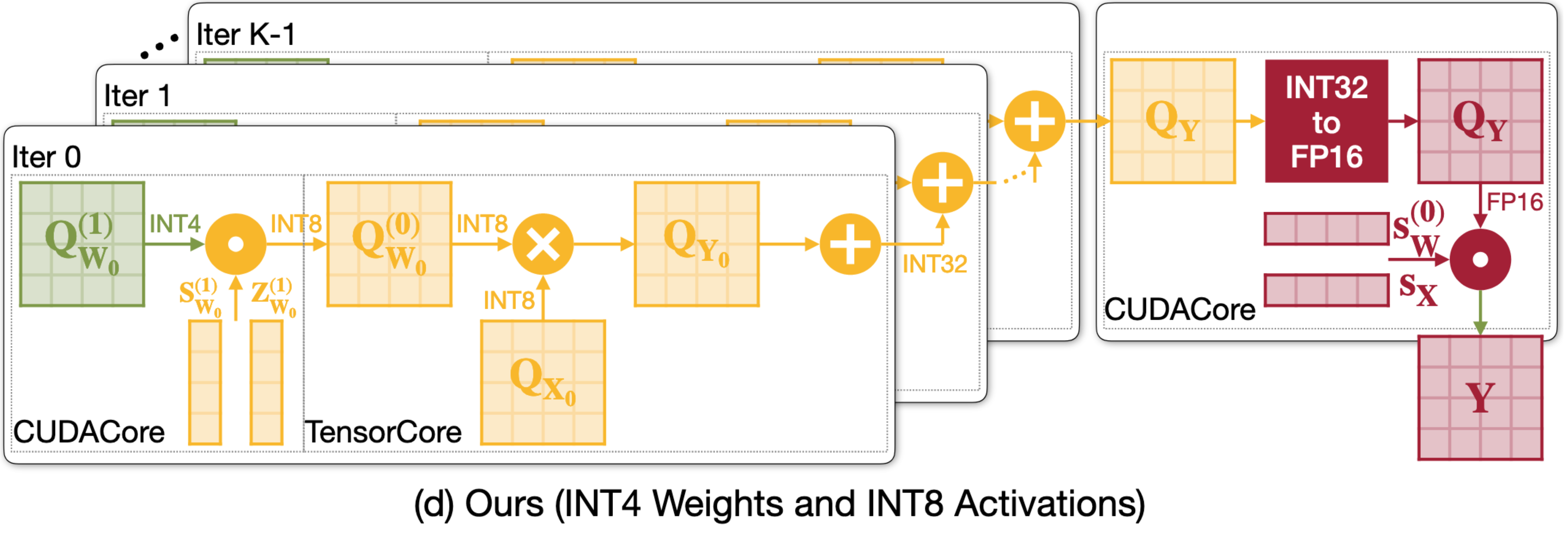
这里其实需要说明一下,有关于Qserve 的量化算法的部分,这里存在一些需要仔细解释的点,就是其中其实进行了两段量化, 请你注意上图中左侧的S(1)和 Z(1),这两个其实是 INT8 类型的(不然没法送到 INT8 的 Tensor Core 里面计算)因此,这里就会有一个问题,如何对于 scaling factor 和 zero point进行量化呢?因此 Qserve 提出了下面的量化策略:
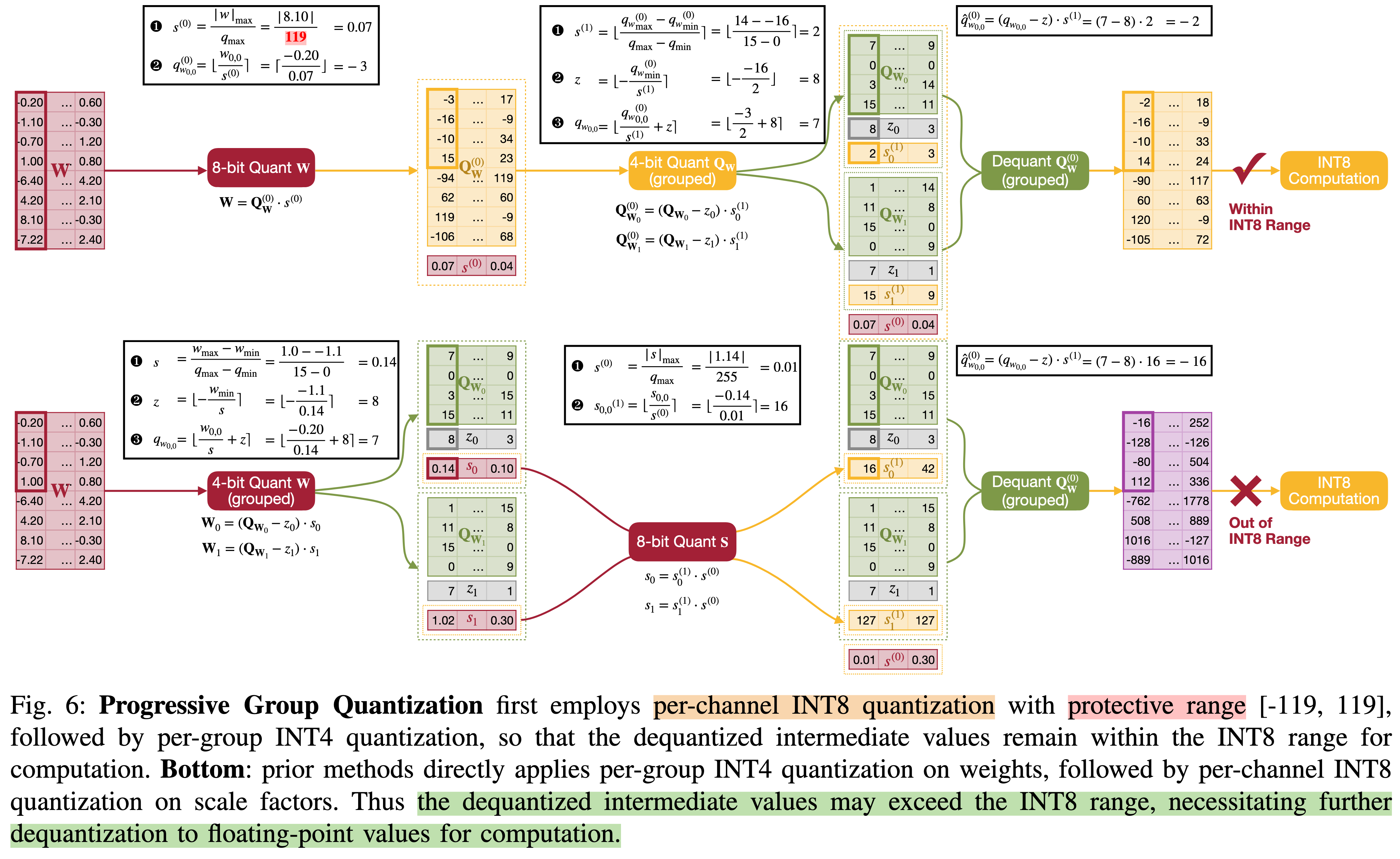
上面其实叙述了两种 two-level 的量化模式:
先进行 INT4 的量化,之后对于其scaling factor、zeropoint 进行 INT8 的量化,这样就是 DGQ 的传统方法,但是这样的方法会导致一个问题就是,会出现溢出的情况,导致后面反量化的结果超过 INT8 的范围。
另外就是QServe 中叙述的 QoQ 的量化方式,这种方式先进行 INT8 的量化是,之后对于量化的 INT8 的值再分成 INT4xINT4 的量化过程。
另外一个需要讨论的事情就是为什么不用 INT4xINT4的这样二级量化过程,这里我先简单解释下:
一般来讲,如果量化数值部分为INT4 的话,那么 scaling factor 和 zero point 的部分数值就会很大,如果此时还用 INT4 进行量化的话,会导致比较大的量化误差,因此不能使用这种方法。
ChatGPT 跟我说不支持 INT4 的 Tensor core,我觉得纯属扯淡。
系统协同设计:QServe Runtime
此外,QServe 兼容 vLLM/TensorRT-LLM 的 in-flight batching 与分页 KV 管理,在生产环境中可直接替换后端(github.com)。
效果评估
吞吐:在 A100 上 Llama-3-8B 最大批量吞吐提升 1.2×,L40S 上提升 1.4×;Qwen-72B 提升最高 3.5×,且 L40S + QServe 性能反超 A100 + TensorRT-LLM(arxiv.org, mlsys.org)。
显存与成本:权重 4-bit 与 KV4 令总显存缩减 2.2–2.5×,结合 L40S 显著降低每 token 成本(论文估算 3×)(hanlab.mit.edu, mlsys.org)。
精度:在 WikiText-2 perplexity、MMLU 等基准上,QoQ 的平均误差劣化 ≤ 0.1 pp,相比 Atom(W4A4)提升 0.3–0.5 pp,同等精度下吞吐更高(openreview.net, emergentmind.com)。
消融:去掉权重重排或寄存器解量化,吞吐分别下降 18 % 和 25 %;不用 SmoothAttention 时 KV4 精度损失扩大至 1.6 pp(arxiv.org, openreview.net)。
与其他方案比较
结论与启示
QServe 的成功表明:
把激活位宽保持在 8 bit,再用双阶段量化把权重压到 4 bit,可让重型 GEMM 完全落在 INT8 Tensor Core,避免 CUDA 核心沦为瓶颈;
关注 KV-cache 同样关键,SmoothAttention 证明只需轻量算法即可在 4 bit 下维持注意力精度;
系统级重排与并行解量化 是让低位宽量化真正跑快的必要条件。未来可在此框架上探索更细粒度的激活混合精度或与稀疏注意力结合,进一步降低数据中心推理成本。(hanlab.mit.edu, chatpaper.com)