QuantSpec: Self-Speculative Decoding with Hierarchical Quantized KV Cache
在长上下文 LLM 推理中,QuantSpec 通过“层次化 INT4/INT8 KV 缓存 + 双全精度缓冲 + 自我推测式(self-speculative)解码”三板斧,把 KV 缓存这个内存与带宽瓶颈直接量化进速度。核心思路是:① 用与目标模型同架构的草稿模型,但把权重和 KV 缓存都压到 4 bit;② 让草稿和目标共享一份“INT8=INT4↑+INT4↓”的层次化缓存,草稿只读上 4 bit,目标拼回 8 bit;③ 配合两个 G token 大小的全精度缓冲,既维持高接受率 (>90 %) 又把频繁量化/回滚的开销摁到每 G 步一次,从而在 128 k 上下文上拿到 ≈2.5 × 端到端提速,显著优于基于稀疏 KV 的 StreamingLLM/SnapKV 等方案。(arxiv.org, stat.berkeley.edu, stat.berkeley.edu)
1. 研究动机与总体思路
瓶颈诊断:解码阶段算强度远低于屋顶点,长上下文时注意力占时比飙升,KV 缓存成为纯内存带宽瓶颈;而短上下文下则是权重加载更痛。(stat.berkeley.edu)
策略划分:因此 QuantSpec 选择“短文本→权重量化、长文本→KV 量化、介于两者→双量化”的分区优化。(stat.berkeley.edu)
为何自我推测:草稿和目标架构一致带来更高 token 接受率;但若直接复制 KV 会额外翻倍显存,亦难兼顾量化。QuantSpec 用层次化 KV 共享化解此矛盾。(stat.berkeley.edu, stat.berkeley.edu)
2. 关键技术细节
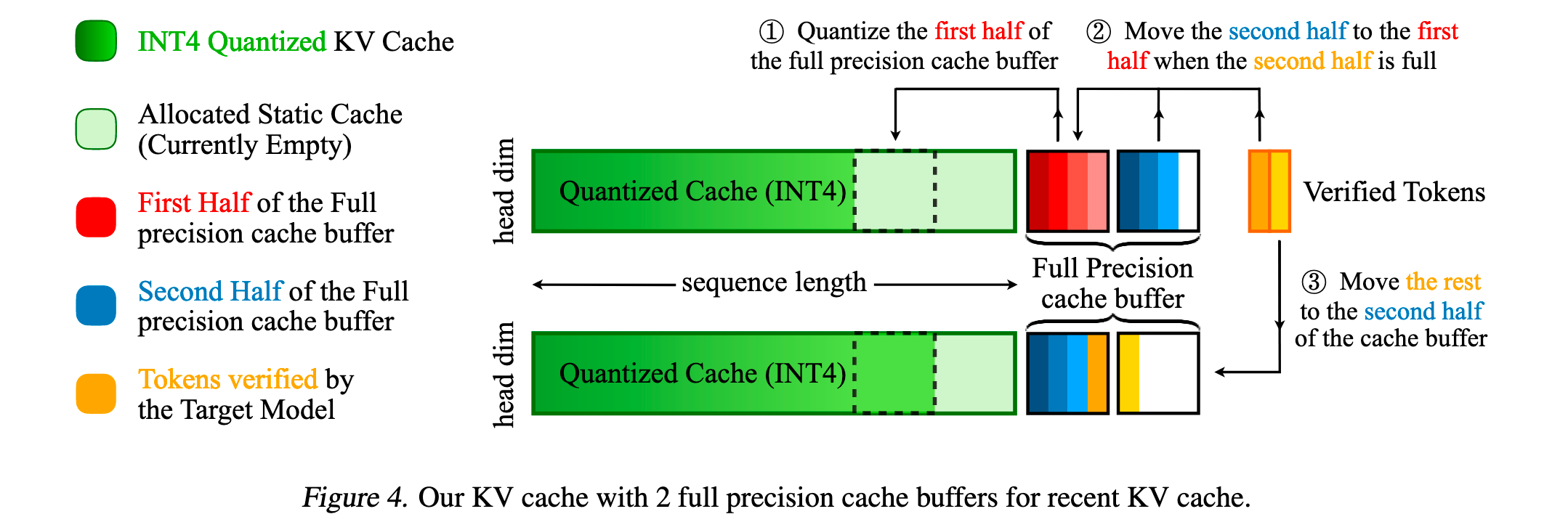
2.1 层次化 INT4/INT8 KV 缓存
CINT8=24 CINT4U+CINT4L,CFP32=CINT8 SINT8+ZINT8C_{INT8}=2^{4}\,C^{U}_{INT4}+C^{L}_{INT4},\quad C_{FP32}=C_{INT8}\,S_{INT8}+Z_{INT8}
将 INT8 拆成高 4 bitC^{U}{INT4}(非对称量化)与残差 4 bitC^{L}{INT4}(对称量化),草稿模型仅加载高 4 bit 做推测;目标模型验证时同时加载两部分恢复到 INT8,再乘以共享缩放S_{INT8} 得近 FP16 质量。(stat.berkeley.edu)
这样草稿与目标共享同一块显存,不再需要两份 KV;同时草稿在推测阶段的内存带宽减半。
2.2 双全精度缓冲 (Double Full-Precision Buffer)
设组大小G(与 head dim 同),维护 CF₁ | CF₂ 两段各 G token 的 FP16 缓存:
prefill:量化历史 KV 至 INT4/INT8,只保留最近 G token 于 CF₁;
decode:新 token 进 CF₂;满 2 G 时等待目标验证;若接受→量化 CF₁ 追加 INT4 缓存并滚动;若回滚→只改 CF₂,避免重量化;整体量化/搬移频率降到每 G token 一次。(stat.berkeley.edu)
优点:① 保持最近 token 全精度→提升草稿预测一致性;② 把量化开销摊薄;③ 天然支持 Speculative 回退逻辑。
2.3 自我推测式解码流程
flowchart LR
subgraph Draft(Model INT4)
A[输入新 token] --> B[读高4-bit KV]
B --> C[并行生成 γ 个候选]
end
subgraph Verify(Target INT8)
D[拼高+低4-bit KV] --> E[验证 γ 候选]
end
C -->|接受| F[写入 CF₂]; E -->|否| G[回滚 CF₂]
F --> H{CF₂ 满?}
H -- 否 --> A
H -- 是 --> I[量化 CF₁ 追加 INT4]; I --> J[CF₂→CF₁ 滚动]; J --> A
3. 自定义 INT4 Attention Kernel
为层次化 KV 写了 INT4/INT8 专用 CUDA kernel;当草稿仅用上 4 bit 时可少读半带宽,测得 128 k 序列下 2.88 × 快于 FP16 FlashAttention。(stat.berkeley.edu)
4. 性能评估
5. 与稀疏 KV 自推测方法对比
6. 实践要点与可能改进
组大小 G:默认用 head dim≈128;更大 G 减少量化频率但可能伤接受率,需任务微调。
草稿-目标权重量化:草稿 INT4 权重 + FP16 激活是默认;若 GPU INT4 TensorCore 友好,可尝试草稿 INT4 matmul 进一步节能。(paperswithcode.com)
与 FlashDecoding 兼容:双缓冲机制可与 token parallel / 多头多核并行共存,论文附录已给示例。(stat.berkeley.edu)
结合稀疏 KV:作者指出未来可叠加剪枝,把层次缓存当做稀疏方法的“落盘格式”,潜在再降显存。(stat.berkeley.edu)
参考文献(选摘)
Tiwari R. et al. QuantSpec: Self-Speculative Decoding with Hierarchical Quantized KV Cache. 2025.(arxiv.org)
OpenReview 讨论与增补材料.(openreview.net)
论文 PDF 技术细节与公式.(stat.berkeley.edu)
层次化 KV 图解(博客 Moonlight 评述).(themoonlight.io)
CUDA kernel 加速表格 (Table 5).(stat.berkeley.edu)
PapersWithCode 综述页面.(paperswithcode.com)
HuggingFace Daily Papers 索引.(huggingface.co)
作者主页补充说明.(haochengxi.github.io)
X.com 讨论帖.(x.com)
其他表格与实验结果行 (Table 4).(stat.berkeley.edu)